
5月14日,写一下猪肉预测价格的作业
CNN+LSTM+GRU
时间序列模型
作业的两大挑战
特征处理(Out-Of-Distribution)
模型构建(Nosiy-Labels)
爬取数据集
数据集
| Date | Price |
|---|---|
| 2025/2/9 | 15.34 |
| 2025/2/10 | 15.46 |
| 2025/2/11 | 15.56 |
| 2025/2/12 | 15.02 |
| 2025/2/13 | 14.44 |
| 2025/2/14 | 15.3 |
| 2025/2/15 | 14.62 |
| 2025/2/16 | 14.58 |
| 2025/2/17 | 14.64 |
| 2025/2/18 | 14.76 |
| 2025/2/19 | 14.74 |
| 2025/2/20 | 14.84 |
| 2025/2/21 | 14.88 |
| 2025/2/22 | 14.79 |
| 2025/2/23 | 14.75 |
| 2025/2/24 | 14.73 |
| 2025/2/25 | 15.04 |
| 2025/2/26 | 14.68 |
| 2025/2/27 | 14.66 |
| 2025/2/28 | 14.57 |
| 2025/3/1 | 14.84 |
| 2025/3/2 | 14.82 |
| 2025/3/3 | 14.81 |
| 2025/3/4 | 14.64 |
| 2025/3/5 | 14.66 |
| 2025/3/6 | 14.59 |
| 2025/3/7 | 14.7 |
| 2025/3/8 | 14.52 |
| 2025/3/9 | 14.5 |
| 2025/3/10 | 14.65 |
| 2025/3/11 | 14.67 |
| 2025/3/12 | 14.66 |
| 2025/3/13 | 14.77 |
| 2025/3/14 | 14.67 |
| 2025/3/15 | 14.75 |
| 2025/3/16 | 14.63 |
| 2025/3/17 | 14.66 |
| 2025/3/18 | 14.67 |
| 2025/3/19 | 14.69 |
| 2025/3/20 | 14.74 |
| 2025/3/21 | 14.77 |
| 2025/3/22 | 14.89 |
| 2025/3/23 | 14.69 |
| 2025/3/24 | 14.65 |
| 2025/3/25 | 14.68 |
| 2025/3/26 | 14.68 |
| 2025/3/27 | 14.68 |
| 2025/3/28 | 14.64 |
| 2025/3/29 | 14.59 |
| 2025/3/30 | 14.56 |
| 2025/3/31 | 14.59 |
| 2025/4/1 | 14.62 |
| 2025/4/2 | 14.7 |
| 2025/4/3 | 14.79 |
| 2025/4/4 | 14.79 |
| 2025/4/5 | 14.66 |
| 2025/4/6 | 14.66 |
| 2025/4/7 | 14.73 |
| 2025/4/8 | 14.81 |
| 2025/4/9 | 14.76 |
| 2025/4/10 | 14.66 |
| 2025/4/11 | 14.67 |
| 2025/4/12 | 14.67 |
| 2025/4/13 | 14.74 |
| 2025/4/14 | 14.81 |
| 2025/4/15 | 14.93 |
| 2025/4/16 | 14.97 |
| 2025/4/17 | 14.94 |
| 2025/4/18 | 14.95 |
| 2025/4/19 | 14.98 |
| 2025/4/20 | 15.07 |
| 2025/4/21 | 15.01 |
| 2025/4/22 | 14.99 |
| 2025/4/23 | 15.05 |
| 2025/4/24 | 15.06 |
| 2025/4/25 | 14.99 |
| 2025/4/26 | 14.97 |
| 2025/4/27 | 14.94 |
| 2025/4/28 | 14.86 |
| 2025/4/29 | 14.86 |
| 2025/4/30 | 14.87 |
| 2025/5/1 | 14.86 |
| 2025/5/2 | 14.9 |
| 2025/5/3 | 14.85 |
| 2025/5/4 | 14.87 |
| 2025/5/5 | 14.85 |
| 2025/5/6 | 14.86 |
| 2025/5/7 | 14.87 |
| 2025/5/8 | 14.9 |
| 2025/5/9 | 14.86 |
| 2025/5/10 | 14.85 |
| 2025/5/11 | 14.87 |
| 2025/5/12 | 14.87 |
代码预测
导入第三方库
import numpy as np |
设置matplotlib的中文支持
# 设置支持中文的字体 |
注意力机制
class Attention(nn.Module): |
特征处理
# 提取时间特征 |
创建训练数据集和测试数据集
# 定义数据集类 |
定义模型
# 定义多层LSTM-GRU混合模型 |
定义超参数
# 设置超参数 |
模型训练
# 训练模型 |
可视化
plt.figure(figsize=(14, 5)) |
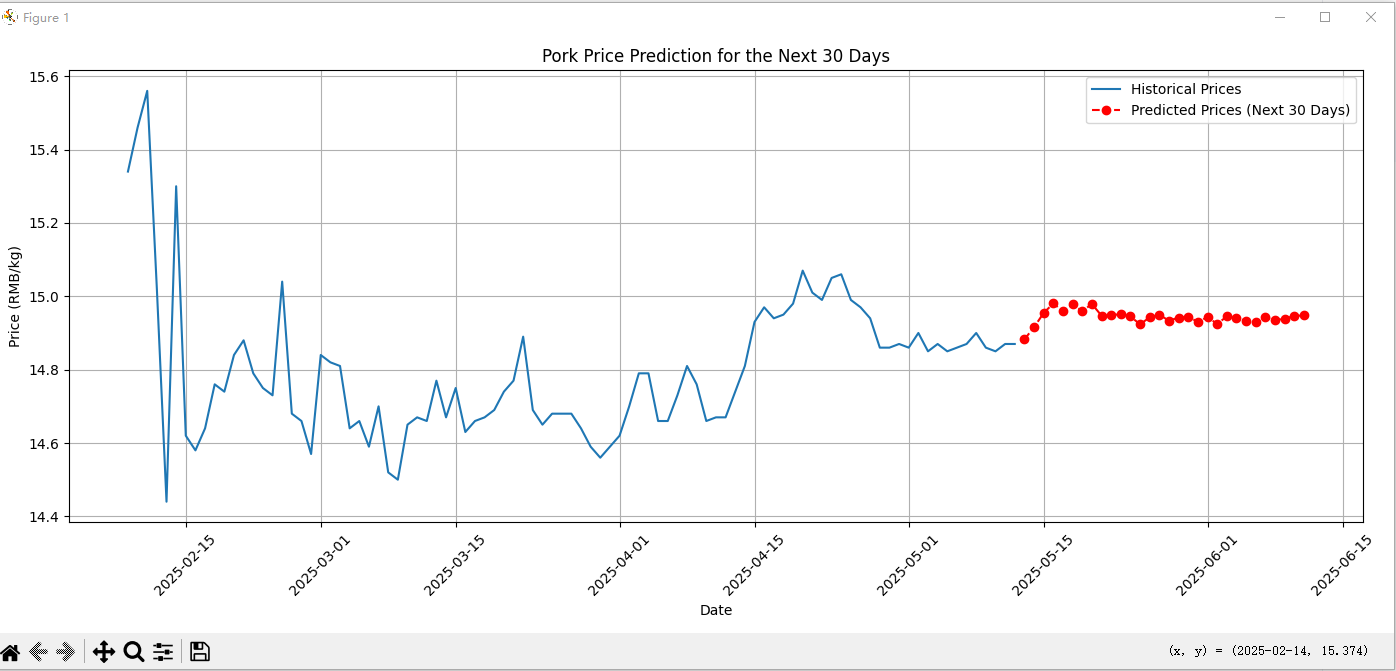
这是预测未来的猪肉价格
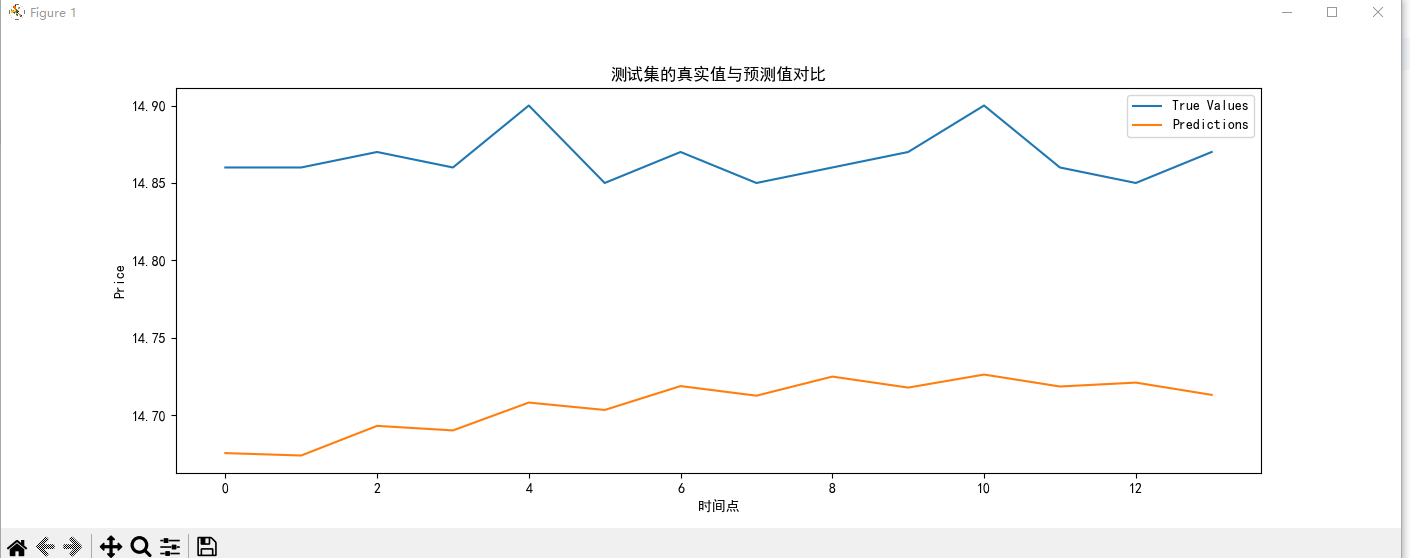
测试集可视化
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Whz's Note!
相关推荐

2025-04-26
Home_back_回家时间
4月26日,坐火车回家

2025-04-24
带带大师兄营业了
4月24日,今天事情好多啊,下午开组会指导本科生写论文,晚上还得给本科生改代码。Causal Partial Label Learning因果表征偏标记学习 数据集的两大挑战领域外泛化问题(Out-Of-Distribution) 候选标签集合(Nosiy-Labels) 计划如下 检查论文内容 检查论文公式 检查论文引用 检查论文格式 改模型改代码 写实验写总结 提交 这是模型流程图 这是模型结果图 偏标记代码 偏标记构造函数 #对标签 y 进行独热编码并转化为torch向量def binarize_class(y): label =...

2025-04-23
LSTM入门教程
4月23日,晴天,是上午10点起床的今天的任务,尝试着美化一下页面 LSTM的深度学习作业今天抽空面向kimi编程写完交一下 // FileName: LSTM.py#!/usr/bin/env python# -*- coding:UTF-8 -*-'''@Project:pythonProject1@File:LSTM3.py@IDE:pythonProject1@Author:whz@Date:2025/4/23 10:20'''# 设置支持中文的字体#预测未来的8个值#跳步时间窗口#预测未来多个数值"""数据集查看以及分析:Server, Value, Timestamp, Questionable, Annotated, Substituteddata =...

2025-04-22
Markdown入门基础
4月22日,阴天,是上午12点起床的 Markdown是什么 要表示标题,只需要在短语面前添加一个井号即可。或者要加粗一个短语只须在短语前后各加两个星号即可 Markdown是独立于平台的,可以在任何操作系统的任何设备上创建Markdown格式的文本 Markdown文档,速查文档Markdown语法教程 2.1标题不同数量的’#’可以完成不同的标题,如下: 一级标题二级标题三级标题2.2 字体粗体,斜体,粗体和斜体,删除线,需要在文字前后加不同的标记符号。如下:这是粗体这是斜体这是粗体加斜体这里想用删除线注:如果想给字体换颜色,或者字体居中显示,需要使用内嵌HTML来实现。 这段文字是红色的! 这段文字是蓝色的。 2.3 无序列表无序列表的使用,在符号’-‘后加空格使用。如下: 无序列表 1 无序列表 2 无序列表 3如果要控制列表的层级,则需要在符号’-‘前使用空格。如下: 无序列表 1 无序列表 2 无序列表 2.1 无序列表 2.2 2.4 有序列表有序列表的使用,在数字及符号’.’后面加空格后输入内容,如下: 有序列表 1 有序列表 2 有序列表...

2025-04-25
GmaePot_游戏时间
4月25日,打了一天游戏。

2025-04-19
Hello World
Welcome to Whz’s Note! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub. Quick StartCreate a new post$ hexo new "My New Post" More info: Writing Run server$ hexo server More info: Server Generate static files$ hexo generate More info: Generating Deploy to remote sites$ hexo deploy More info: Deployment
评论
LivereWaline

